Hello,
I’m facing an issue with discovery jobs stuck in Running state on my Centreon platform.
Context
-
Multiple discovery jobs configured per poller
-
Providers used:
-
VMware (ESXi & VM discovery, ~20 jobs with filters)
-
AWX (2 jobs: pre-prod and prod)
-
-
Pollers are sized according to Centreon recommendations
-
Jobs are scheduled sequentially with intervals, running once per day
Issue
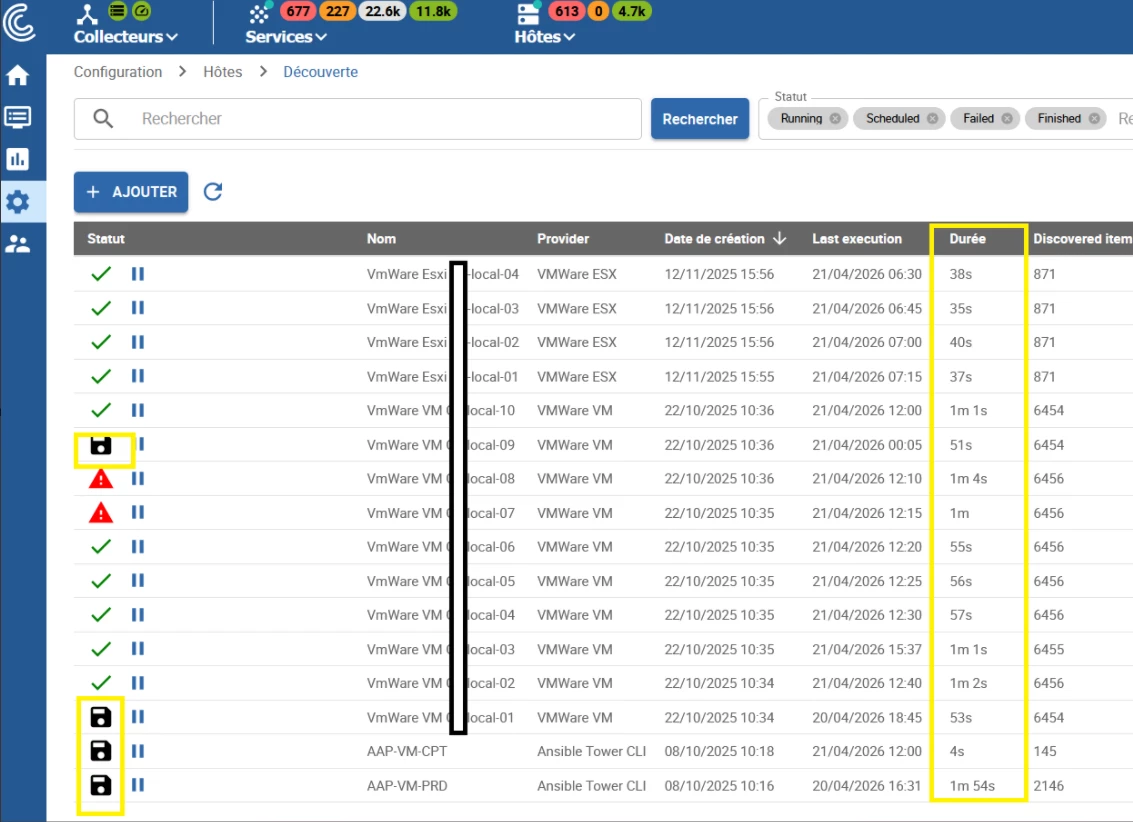
Recently, some discovery jobs are getting stuck in Running state indefinitely.
-
On the central server, I get errors indicating that the job cannot be launched because it is already in Running state
-
It is impossible to restart the job from the UI (even after waiting a long time and after restarting gorgoned service )
Checks already performed
-
Reviewed
gorgonedlogs on central and pollers -
Checked VMware daemon logs on pollers
-
No explicit errors found explaining the blockage
-
Verified that jobs are not overlapping by design (sequential scheduling)
Observations
-
The issue appeared recently (no major known change)
-
Affected jobs never exit Running state
-
New executions are blocked because of this status
Questions
-
Has anyone already faced discovery jobs stuck in Running state?
-
Are there known issues with VMware or AWX providers causing this behavior?
Any help or feedback would be greatly appreciated.
Best regards,