

Monitoring an IT infrastructure is a stressful job, especially for businesses that depend on it. And even though most monitoring solutions have capabilities to be proactive, the reality is that the main feature used in those software is real time monitoring, and fixing any issue when they happen.
And because IT systems tend to become more and more complex (thank you second law of thermodynamics), we end up with intricate services. And if one of them fails, then few if not many of them will fail as well. And we end up with this: 
[...] one of the unintended consequences of a growing number of alerts is the potential for user desensitization. This desensitization has also been called “alert fatigue,” “cry-wolf syndrome,” and “pop-up fatigue.” Greengold’s tongue-in-cheek commentary “Chronic Alert Fatigue Syndrome: An In-Your-Face-Dilemma” humorously illustrates the level to which this problem has risen. Alert fatigue can be compared to the law of diminishing returns in economics, to the saturation point in chemistry, and to Shakespeare’s As You Like It, “Why then, can one desire too much of a good thing?”
Even though there is no scientific consensus on how to directly mitigate this issue [2], reducing the number of alerts is a first step. And one way to achieve this is to group services that are suspected to have all failed because of the same cause. This is what this article is about.
Status clustering
In Centreon, a resource can have different statuses depending on the value of the metric and the thresholds that are configured. We’ll be focusing on services, which can have 5 different statuses:
- OK The service presents no problem
- WARNING The service has reached the warning threshold
- CRITICAL The service has reached the critical threshold
- UNKNOWN The status of the service cannot be checked (e.g.: SNMP agent down, etc.)
- PENDING The service has just been created and has not been checked yet
Status data
In Centreon, the historical statuses of each service can be found in the `logs` table from the`centreon_storage` database. So let’s export a csv file with the status for each service:
SELECT ctime, CAST(host_name, “-”, service_description), status
FROM logs
WHERE host_name != '' AND service_description != ''
INTO OUTFILE 'centreon_statuses.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
The output file is now created:
head /var/lib/mysql/centreon_storage/centreon_statuses.csv
1720130514,"host1-service1","Load",1
1720130602,"host1-service2","Load",2
1720130737,"host1-service3","Memory",0
1720130814,"host2-service1","Load",2
1720130842,"host2-service2","Swap",3
1720130902,"host2-service3","Load",2
1720131114,"host3-service1","Load",0
1720131202,"host3-service2","Load",2
1720131414,"host3-service3","Load",1
1720131502,"host4-service1","Load",2Keep this request and this result in mind, we’ll be using them very soon.
Status forensic
The idea of grouping services based on status uses the same technique used by forensics to identify relatives. Our genetics is based on DNA, which is basically a very long sequence of 4 proteins (adenine (A), thymine (T), guanine (G), and cytosine (C)).
DNA representation, credit to OpenStax College, Anatomy and Physiology I, Chapter 2 - Protein Synthesis
Relatives will have common patterns within the DNA, and the closer they are in the genealogic tree, the more they’ll have identical sequences.
Going back to Centreon status, for each service we can build a sequence of status and compare this sequence to all the other services. Let’s take the first letter of the status to determine the status protein: O for OK, U for Unknown, W for Warning and C for Critical. Let’s forget about the Pending status here which is less relevant.
For example, we can have something like:
CaaS-Customer-Cloud-Centreon-ReportsCentreonMap:MAP-Health: COCCCCOOCCCCOOOWhich indicates that the MAP health on the cloud server hosting “reports centreon MAP” was critical, then OK then critical for 4 checks, then OK for 2 checks, …
Now if we compare it to another service:
CaaS-Customer-Cloud-Customer1:Ping: CCCCOOCOCCCCOOCWe have almost the same sequence. Out of 15 checks that were performed on those services, only 4 of them differ. Which means that almost 75% of the time when one service is down, the other one is down too.
Although we’re not saying both of them are related, it is worth noting that they seem to behave the same way and therefore group them.
Calculate distances
We understand now what we want to do: compare 2 sequences of statuses and see how much they differ. There are different ways to compute the distance between 2 sequences, for example:
- Levenshtein Distance which measures the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one string into another
- Jaccard Index which compares the similarity between two sets by dividing the size of their intersection by the size of their union
Along with this article, you can find on our Centreon Labs github repository a command line that will output the distance between one service and all the other ones:
❯ csi distance -t 8 data/centreon_statuses.csv CaaS-Customer-cloud-Customer1:Ping
Distances for ID CaaS-Customer-cloud-Customer1:Ping above 8.0 using levenshtein:
CaaS-Customer-cloud-Customer1:Ping : 0.0
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:MAP-Health : 4.0
CaaS-Customer-cloud-Customer2:proc-broker-rrd : 6.0
centreon.com:HTTP-Response-Time : 7.0
CaaS-Customer-cloud-Customer3:Centreon Cloud login page : 8.0
CaaS-Customer-cloud-Customer4:Centreon Cloud login page : 8.0
CaaS-Customer-cloud-Customer5:Centreon Cloud login page : 8.0
CaaS-Customer-cloud-Customer6:Centreon Cloud login page: 8.0In this example, we can see 8 services that are relatively close to the one we studied. By the name of those services, it does seem that it is not unbelievable that those services are related somehow but only a real expert of this IT architecture will be able to tell for sure.
And because all we do is comparing 2 strings together, nothing stops us from finding the closest hostname or service description to the one we chose:
❯ csi distance -t 20 data/centreon_statuses.csv CaaS-Customer-cloud-Customer1:Ping --compare-names
Distances for ID CaaS-Customer-cloud-Customer1:Ping above 20.0 using levenshtein:
CaaS-Customer-cloud-Customer1:Ping : 0.0
CaaS-Customer-cloud-Customer2:Load : 8.0
CaaS-Customer-cloud-Customer3:Load : 9.0
CaaS-Customer-cloud-Customer4:Load : 9.0
CaaS-Customer-cloud-Customer5:Load : 11.0
CaaS-Customer-cloud-Customer6:Load : 14.0
CaaS-Customer-cloud-Customer7:Load : 16.0
CaaS-Customer-cloud-Centreon-ReportsCentreon:Load: 20.0
CaaS-Customer-cloud-Centreon-ReportsCentreon:Cpu : 20.0Note that the names of the customers have been anonymized after the distance calculation.
Funny that we see some overlap here!
Find clusters
We now know how to compare two sequences of statuses together. We can then calculate all distances pairwise. If we want to be fancy, we can plot those distances in a heatmap:
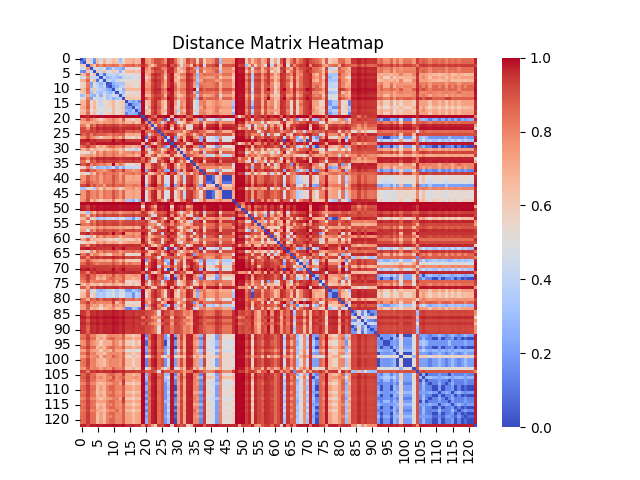
Here we compare around 120 services together. This heatmap is made of 120 x 120 = 14400 pixels. Each pixel is colored based on the distance between the two services at their corresponding coordinates. Even though this heatmap does not tell us anything about the architecture of our IT system, we can visually spot that there are some areas that look very close. Finding groups of services that are close to each other is the clustering phase.
And because we don’t know how many clusters we can have in our system, we need to use a clustering algorithm that will find it for us. One vastly used algorithm is Density-Based Spatial Clustering of Applications with Noise (DBSCAN). If you want to try it out, we also covered this part in our `csi` command line:
csi cluster data/centreon_statuses.csv
Cluster -1: 49 services with no cluster
Cluster 1:
TLSE_Zyxel:Sessions
TLSE_Zyxel:Cpu
sage-bastion-prod-root-cloud:Disk-/
AQU-onprem3:onprem-Memory
AQU-FWASA01:Traffic-Interface_inside_vlan2
AQU-FWASA01:Traffic-Interface_inside_vlan99
AQU-FWASA01:Sensors
AQU-FWASA01:Traffic-Interface_inside_vlan20
AQU-FWASA01:Traffic-Interface_outside_Gi0/1
AQU-FWASA01:Traffic-Interface_inside_PC
AQU-FWASA01:Sessions
AQU-FWASA01:Cpu
AQU-FWASA01:Traffic-Interface_outside_Gi0/3
AQU-FWASA01:Memory
AQU-FWASA01:Traffic-Interface_inside_Gi0/2
AQU-FWASA01_1:Sensors
AQU-FWASA01_1:Cpu
AQU-FWASA01_1:Memory
AQU-FWASA01_1:Sessions
AQU-FWASA01_1:Traffic-Interface_outside_Gi0/1
AQU-FWASA01_1:Traffic-Interface_inside_vlan2
AQU-FWASA01_1:Traffic-Interface_inside_vlan99
AQU-FWASA01_1:Traffic-Interface_outside_PC
AQU-FWASA01_1:Traffic-Interface_inside_PC
AQU-FWASA01_1:Traffic-Interface_inside_vlan10
AQU-FWASA01_1:Traffic-Interface_outside_Gi0/3
AQU-FWASA01_1:Traffic-Interface_inside_Gi0/2
AQU-FWASA01_1:Traffic-Interface_inside_vlan20
AQU-FWASA01_1:Traffic-Interface_inside_Gi0/0
AQU-SW01-02:SW02-Interface-2-onprem01
AQU-SW01-02:SW02-Interface-1-onprem02
AQU-SW01-02:SW02-Interface-2-onprem02
AQU-SW01-02:SW01-Interface-2-onprem02
Cluster 2:
AQU-onprem3:onprem-Swap
AQU-onprem2:onprem-Cpu
AQU-onprem4:onprem-Cpu
AQU-onprem2:onprem-Swap
AQU-onprem3:onprem-Cpu
AQU-onprem4:onprem-Swap
Cluster 3:
ACP-PASOL-603:Ping
CaaS-Customer-cloud-Customer1:Centreon Cloud login page
ACP-PASOL-701:Ping
CaaS-Customer-cloud-Customer2:Centreon Cloud login page
CaaS-Customer-cloud-Customer3:Load
SWI-PASOL-600:Ping
CaaS-Customer-cloud-Customer4:Centreon Cloud login page
centreon.com:HTTP-Response-Time
CaaS-Customer-cloud-Customer5:Centreon Cloud login page
CaaS-Customer-cloud-Customer6:proc-broker-rrd
CaaS-Customer-RDS-prod1euwest1Customer7:DatabaseConnections
Cluster 4:
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:MAP-Health
CaaS-Infra-cloud-VPN:Cpu-Detailed
CaaS-Customer-cloud-Customer8:Ping
Cluster 5:
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:Cpu
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:Load
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:Memory
Cluster 6:
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-httpd
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-broker-rrdAgain, each cluster is a group of services whose status sequence were relatively close to each other. We can definitely see a pattern. And the good news is that we can do the same exercise, but by comparing the names instead of the sequence of patterns:
❯ csi cluster data/centreon_statuses.csv --compare-names
Cluster -1: 58 services with no cluster
Cluster 0:
AQU-onprem3:onprem-Swap
AQU-onprem2:onprem-Swap
AQU-onprem4:onprem-Swap
Cluster 1:
AQU-onprem2:onprem-Cpu
AQU-onprem4:onprem-Cpu
AQU-onprem3:onprem-Cpu
Cluster 2:
ACP-PASOL-603:Ping
ACP-PASOL-701:Ping
Cluster 3:
AQU-SW01-02:SW01-Interface-FC
AQU-SW01-02:SW02-Interface-FC
Cluster 4:
AQU-SW01-02:SW01-Interface-1-onprem02
AQU-SW01-02:SW02-Interface-2-onprem01
AQU-SW01-02:SW02-Interface-1-onprem02
AQU-SW01-02:SW02-Interface-2-onprem02
AQU-SW01-02:SW01-Interface-2-onprem02
Cluster 5:
AQU-FWASA01:Traffic-Interface_inside_vlan2
AQU-FWASA01:Traffic-Interface_inside_vlan99
AQU-FWASA01:Traffic-Interface_inside_vlan20
AQU-FWASA01_1:Traffic-Interface_inside_vlan2
AQU-FWASA01_1:Traffic-Interface_inside_vlan99
AQU-FWASA01_1:Traffic-Interface_inside_vlan10
AQU-FWASA01_1:Traffic-Interface_inside_vlan20
Cluster 6:
AQU-FWASA01:Sensors
AQU-FWASA01:Sessions
AQU-FWASA01_1:Sensors
AQU-FWASA01_1:Sessions
Cluster 7:
AQU-FWASA01:Traffic-Interface_outside_Gi0/1
AQU-FWASA01:Traffic-Interface_outside_Gi0/3
AQU-FWASA01_1:Traffic-Interface_outside_Gi0/1
AQU-FWASA01_1:Traffic-Interface_outside_Gi0/3
Cluster 8:
AQU-FWASA01:Traffic-Interface_inside_PC
AQU-FWASA01_1:Traffic-Interface_outside_PC
AQU-FWASA01_1:Traffic-Interface_inside_PC
Cluster 9:
AQU-FWASA01:Cpu
AQU-FWASA01_1:Cpu
Cluster 10:
CaaS-Customer-cloud-Centreon-ReportsCentreon:Load
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:Load
Cluster 11:
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:Cpu
CaaS-Customer-cloud-Centreon-ReportsCentreon:Cpu
Cluster 12:
CaaS-Customer-cloud-Centreon-ReportsCentreonMap:Memory
CaaS-Customer-cloud-Centreon-ReportsCentreon:Memory
Cluster 13:
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-httpd
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-sshd
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-ntpd
Cluster 14:
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-broker-rrd
CaaS-Customer-cloud-Centreon-ReportsCentreon:proc-broker-sql
Cluster 15:
AQU-FWASA01:Memory
AQU-FWASA01_1:Memory
Cluster 16:
AQU-FWASA01:Traffic-Interface_inside_Gi0/2
AQU-FWASA01_1:Traffic-Interface_inside_Gi0/2
AQU-FWASA01_1:Traffic-Interface_inside_Gi0/0We have a bit more clusters here and they all look logical. Some parameters can be adjusted to increase or decrease the size of the clusters, check out the readme for more information.
Conclusion
Grouping services based on their status sequences offers a practical way to cut down on noise and make it easier to find the root cause of issues in complex IT environments. By comparing status patterns, we can highlight services that often fail together, reducing the flood of alerts and helping to combat alert fatigue. This method doesn’t replace the need for expert analysis, but it does provide a helpful shortcut, giving teams a clearer picture of which services might be linked. With these tools in hand, the investigation process becomes less overwhelming and more efficient.
References
- Jared J. Cash, Alert fatigue, American Journal of Health-System Pharmacy, Volume 66, Issue 23, 1 December 2009, Pages 2098–2101, https://doi.org/10.2146/ajhp090181
- Winters BD, Cvach MM, Bonafide CP, Hu X, Konkani A, O'Connor MF, Rothschild JM, Selby NM, Pelter MM, McLean B, Kane-Gill SL; Society for Critical Care Medicine Alarm and Alert Fatigue Task Force. Technological Distractions (Part 2): A Summary of Approaches to Manage Clinical Alarms With Intent to Reduce Alarm Fatigue. Crit Care Med. 2018 Jan;46(1):130-137. doi: 10.1097/CCM.0000000000002803. PMID: 29112077.
Important Note: This article is part of the initiatives from Centreon Labs, a group dedicated to exploring, developing, and experimenting with innovative IT monitoring projects. You are invited to join the Centreon Labs group here on The Watch to discuss, test, and contribute to these projects. Additional resources are also available on our GitHub repository.