What is the best practice to handle stale process from services?
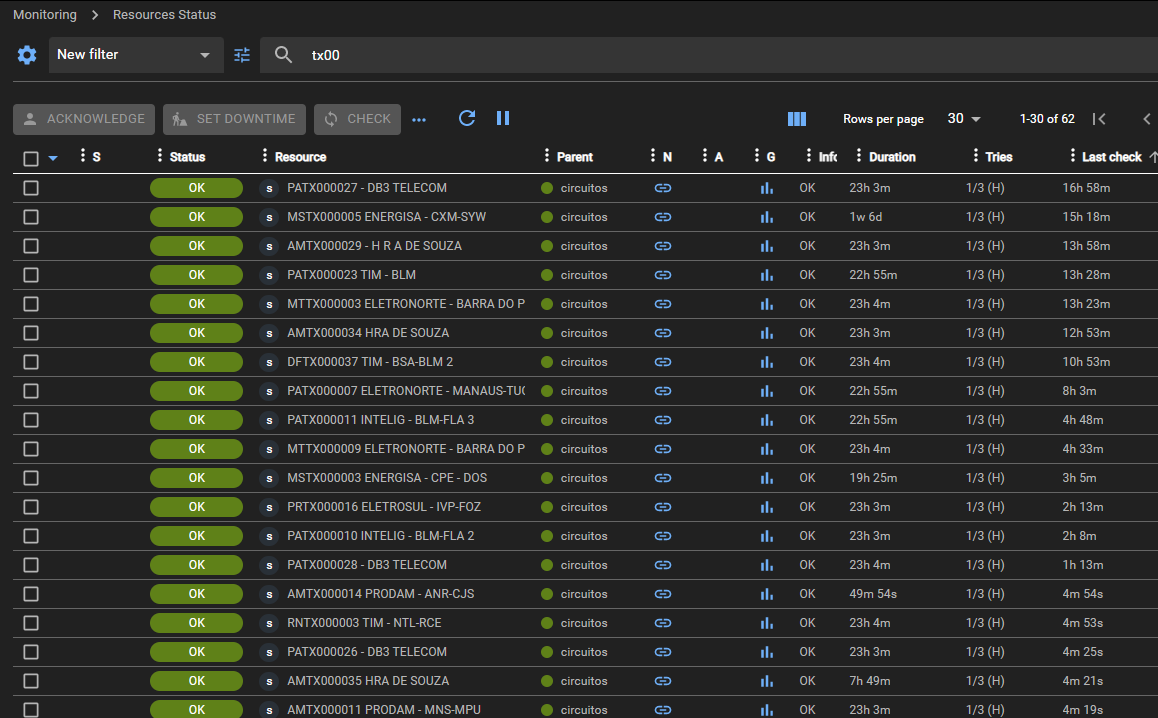
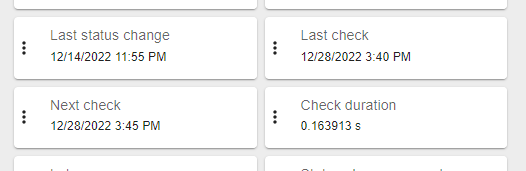
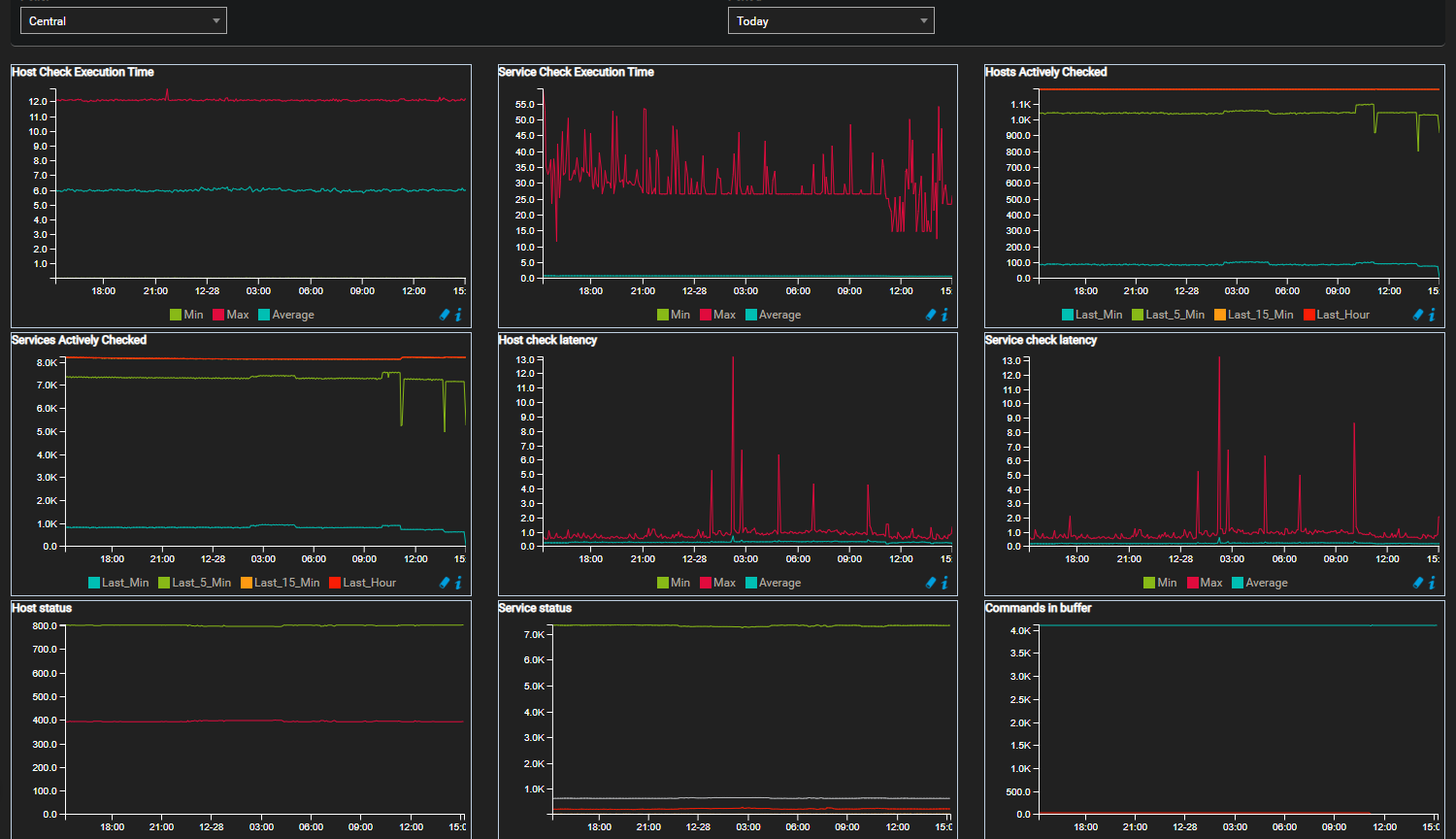
Most of my services have a 5 minutes polling, although some of them have their last check reaching hours.
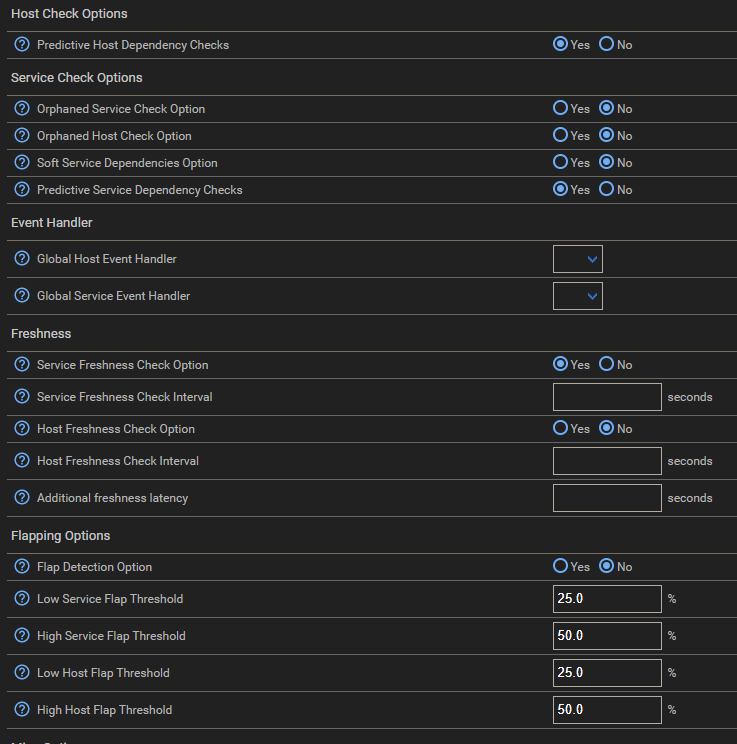
When I list process from centreon-engine they seem to be stuck even with max_execution_time set to 60s
These scripts are basically consulting large MIB tables which runs in 5 seconds average but for some reason they stack in the process pipeline.
I’d like to schedule a script to cleanup those stuck process. Since I don’t want to mess with the system crontab, using a centreon service could be the best way to schedule it. How can I set the right permission to centreon-engine be killing these process though this script?