

I have 3 DB2 servers, all have the same processes (only the DB name are different), they all have the same process check (based on a service template).
The checks worked well for several months, from a few days the check is CRITICAL on 1 server whereas the process is still present. I can’t find why.
Here is the check command from the poller :
/usr/lib64/nagios/plugins/check_centreon_nrpe3 -H XXX0002.domain -p xxxx -t30 -u -c check_centreon_plugins -a ‘os::linux::local::plugin’ ‘process’ ‘--warning-total= --critical-total=1:1 --warning-time= --critical-time= --filter-command="^db2sysc$" --filter-arg="0" --filter-state="" ‘
For XXX0002 it returns :
CRITICAL: Number of current processes: 0 | 'processes.total.count'=0;;1:1;0;
For XXX0001 and XXX0003 it returns :
OK: Process: ecommand => db2sysc] =arg => db2sysc 0] gstate => S] duration: 1y 7M 12h 30m 31s - Number of current processes: 1 | 'processes.total.count'=1;;1:1;0;
When I execute the bash command used by the check, i.e.
ps -e -o state -o ===%t===%p===%P=== -o comm:50 -o ===%a -w 2>&1
then grep “db2sysc”, I can see (on all servers) the DB2 process, including the one I want to monitor :
S===578-19:49:21===2471=== 1===db2syscr ===db2wdog 0 �db2wol]
S===578-19:49:21===2476=== 2471===db2sysc ===db2sysc 0
S===578-19:49:21===2482=== 2471===db2syscr ===db2ckpwd 0
S===578-19:49:21===2483=== 2471===db2syscr ===db2ckpwd 0
S===578-19:49:21===2484=== 2471===db2syscr ===db2ckpwd 0
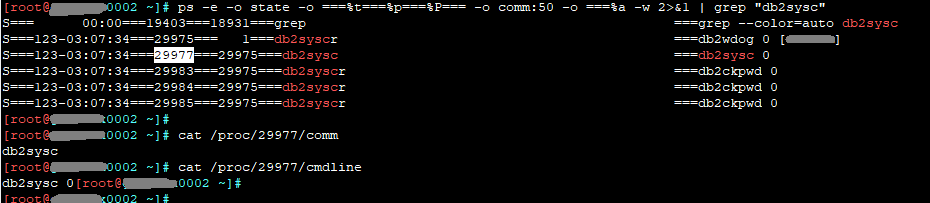
it’s all the same on the 3 servers, the DB are running perfectly.
Why 1 check of 3 could have gone wrong ? 
Centreon 24.04
Check from plugin “OS Linux”, mode process.
Thx for help by advance