We have e Timeperiod linked to 400 services. This timeperiod is set to run the services everyday 08H-10H.
The problem is that the Poller tries to run all of them at 08H00 … which leads to cpu load (on the poller) and also timeouts for some services ….
The services are ran locally on the Poller (Not on remote hosts). The services are configured with a ‘Retry Check Interval = 8 minutes and a ‘Max Check Attempts=8”
I juste need that these services to be run once a day but not necessary at 08H exact time.
I just want to find a way to get these services execution dispatched (spreaded) in the Timeperiod (From 08H to 10H) …
Example: service 1 : run at 08H00 service 2 and service 3 : run at 08H01 service 4: …. run at 08H04 … etc
Any idea ?
Thanks ?
Page 1 / 1
Hello
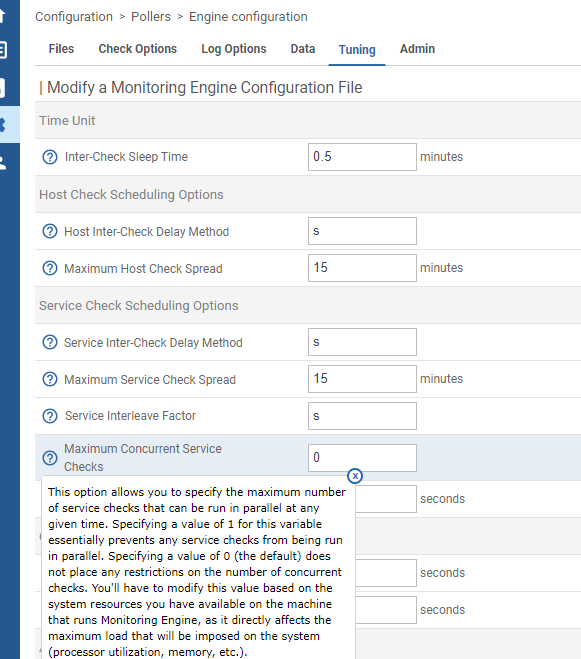
you could check the menu poller/engine configuration and the tab tuning
you have some automatic “spreading” and concurrency options here, beware it may cause latency if you are too restrictive (these are the default option from a fresh new poller created with the web ui wizard 23.10)
Thanks,
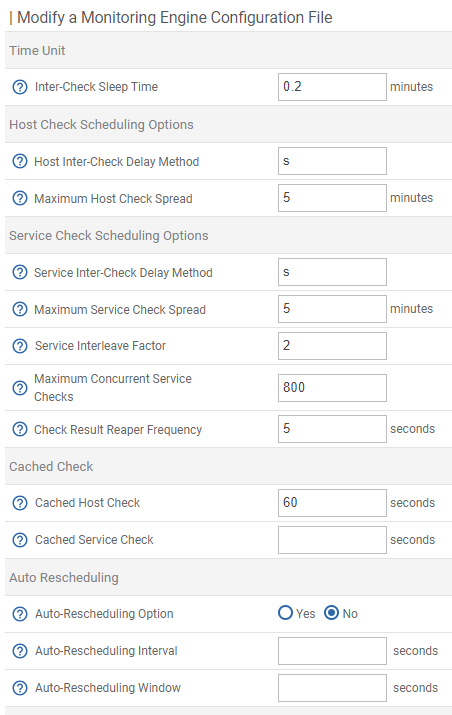
Here are my settings :
I have a ‘Service Interleave Factor’ = 2 maybe I should set it to the default value ? The doc mentions :
s = Use a “smart” interleave factor calculation (default)
We have here 18200 services on 1200 hosts (dispatched on 3 separated pollers).
some of my older poller have an interleave factor set at 2 also, but newer created poller have “s” for smart.
I realized I hadn’t really understood your issue, but I re-read you, and I think I understand, you should try to put the “s” instead of 2, and maybe reduce the 800 concurrent check to a lower value
could you provide more information on the poller sizing :
number of cpu (vcpu, or core/thread)
ram
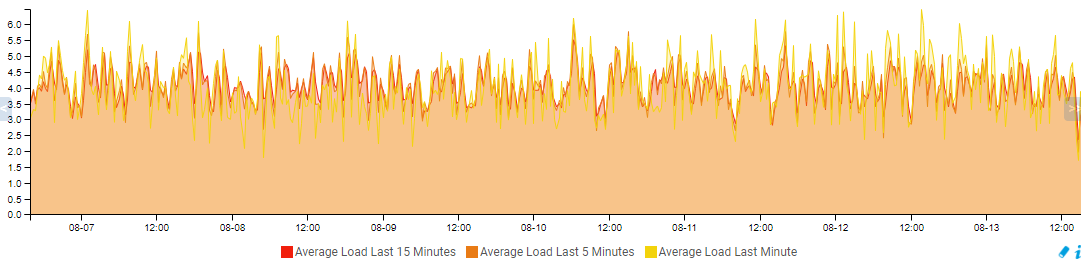
the average load (if you have the central monitoring your poller, it should be there)
(as stated on the tool tips, all this is dependant on the hardware config of your poller)
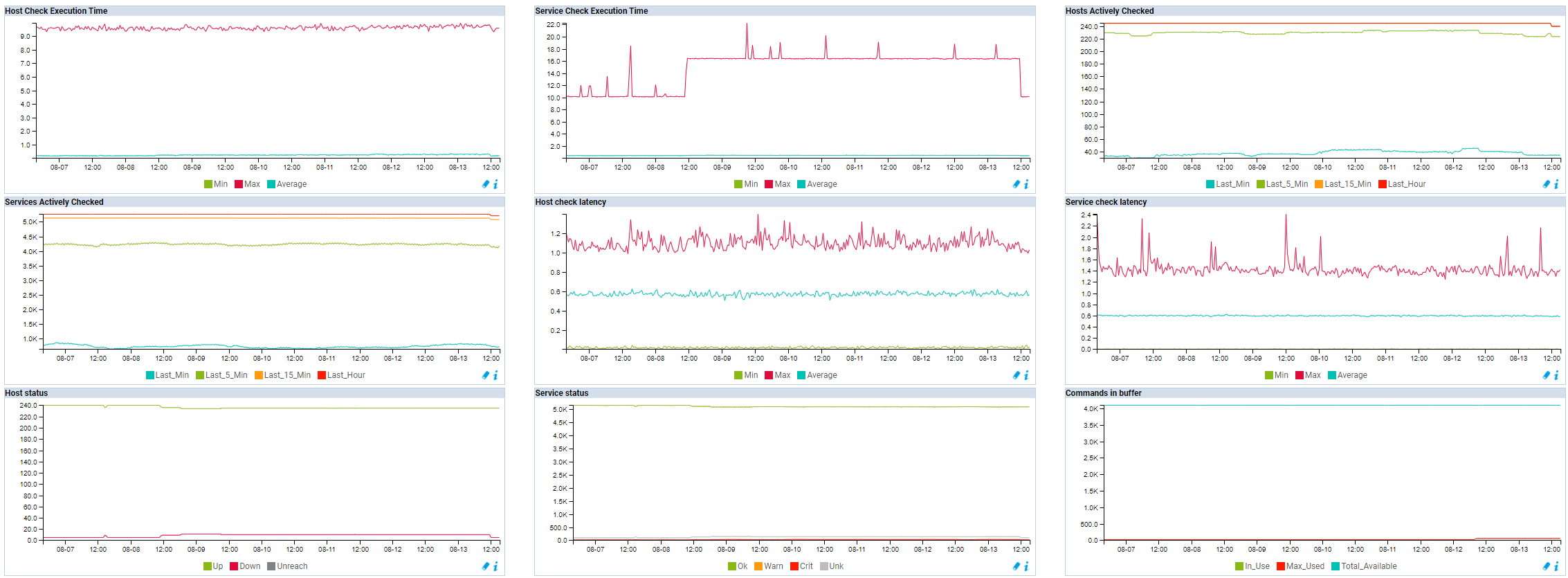
and if possible a screen of the statistic page (from the admin menu, plaform status, engine statistic)
let’s keep the period on 1 week to get a smooth curves
To compare with one of my poller, with 12 vCPU, running 5300~ services, with the default 5 minutes for normal check
active check 5.3k, with 800check per minutes, over 240 hosts (mostly network device so a lot of snmp)
there are no “burst” as there is only 1 time period, 24/7, for monitoring
the load is around 4-6
i had latency and high load with only 8, and I needed to change a few options in tuning, (but this poller is one which has the interleave at 2, i’ll try to put it with “s” and see if it change things, as when I have a network problem, this poller do a lot of retries, which cause a few issues sometimes)