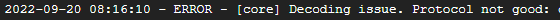Hello,
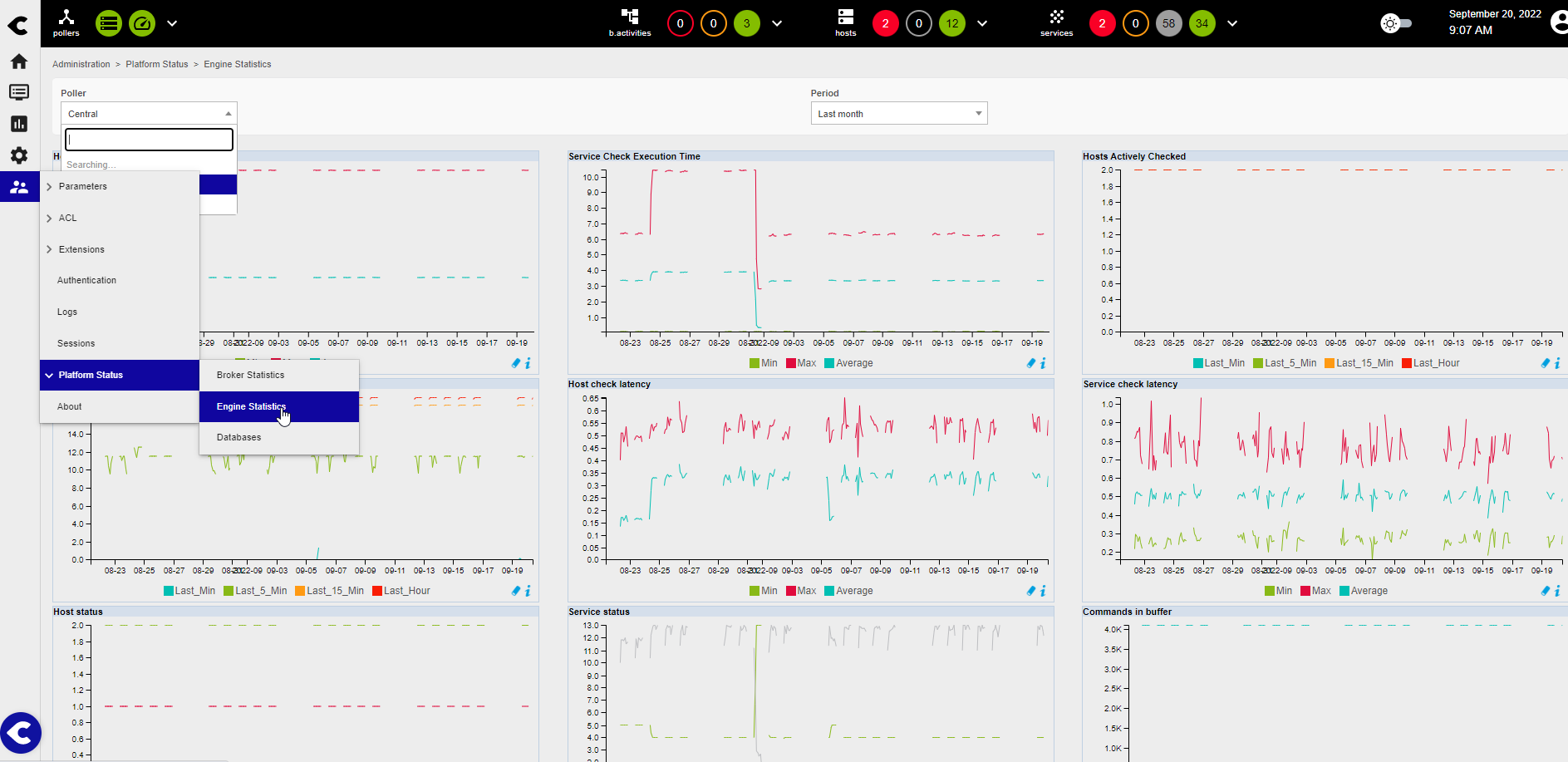
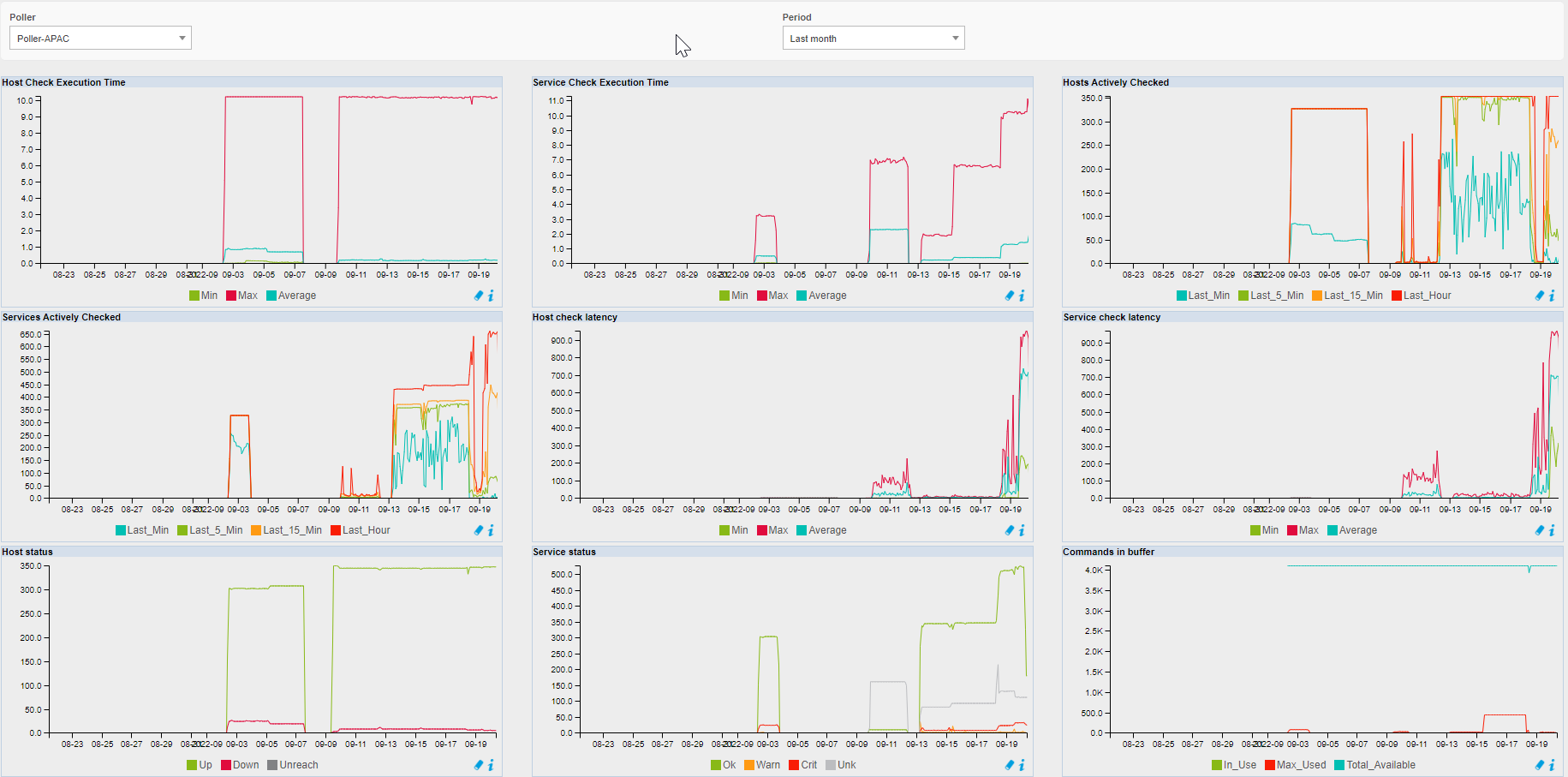
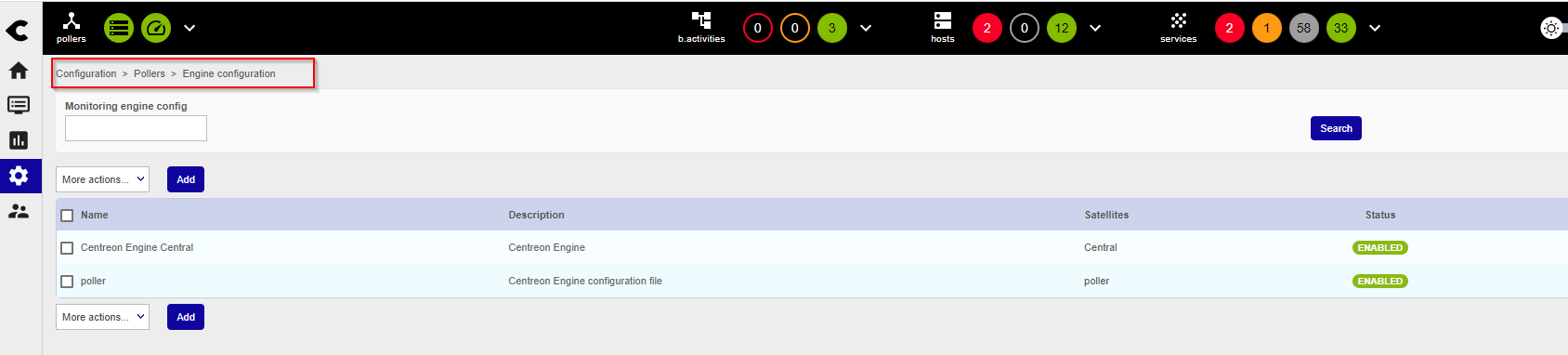
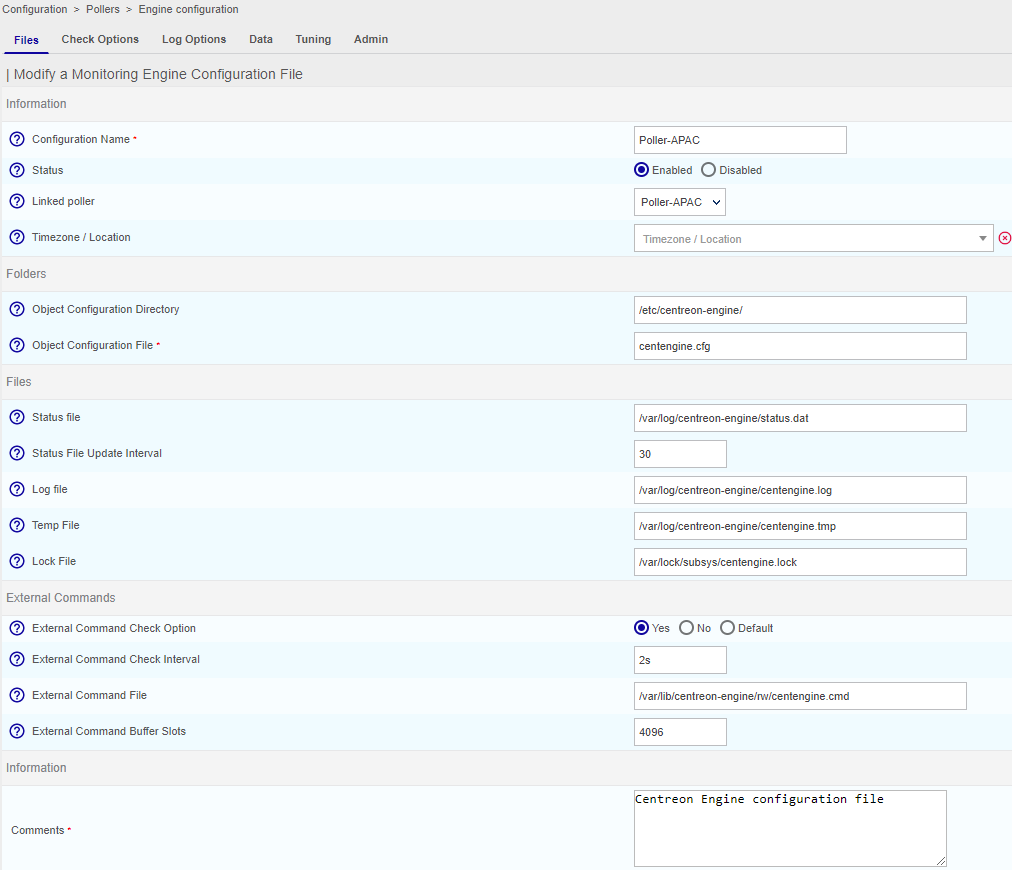
I just finilized installation of Centreon on GCP, my topoligy is 1 central in EMEA and 2 poller 1 in US and another one in Singapore.
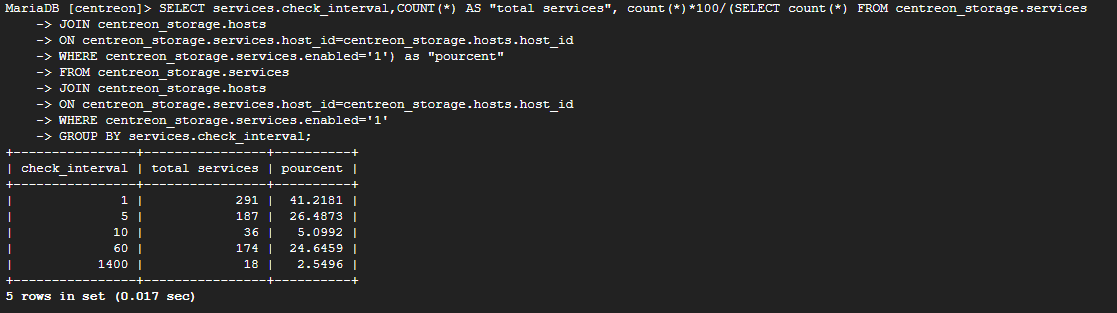
I monitor 1000 hosts and 5000 services.
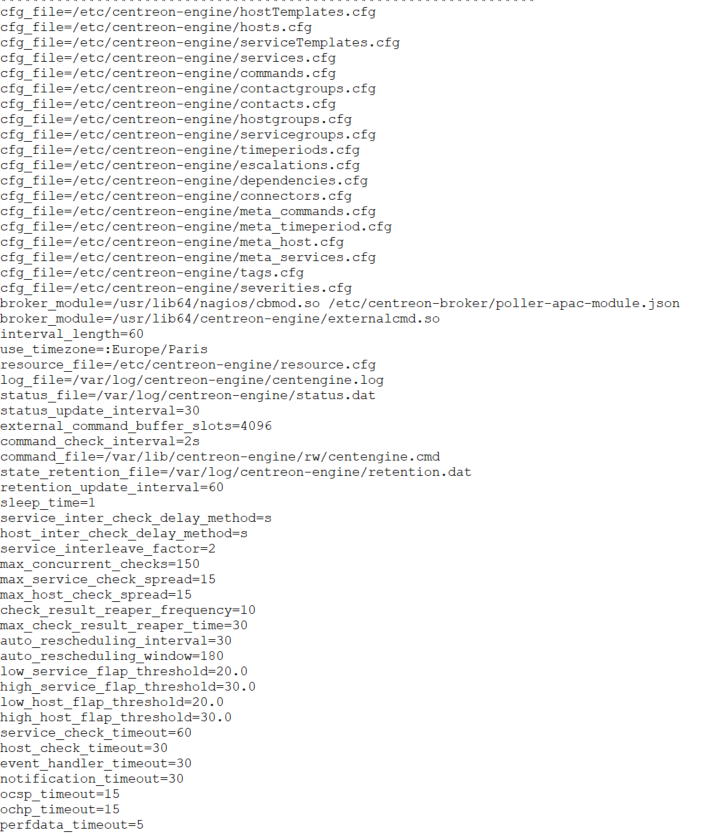
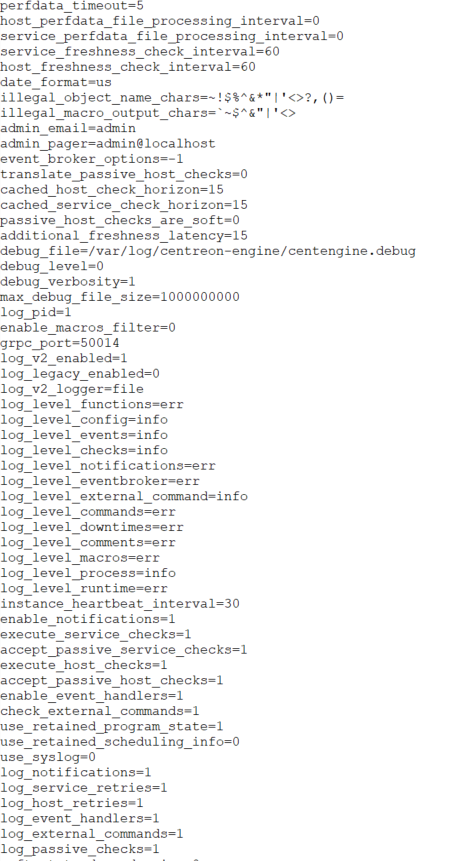
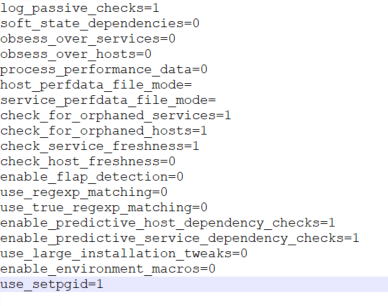
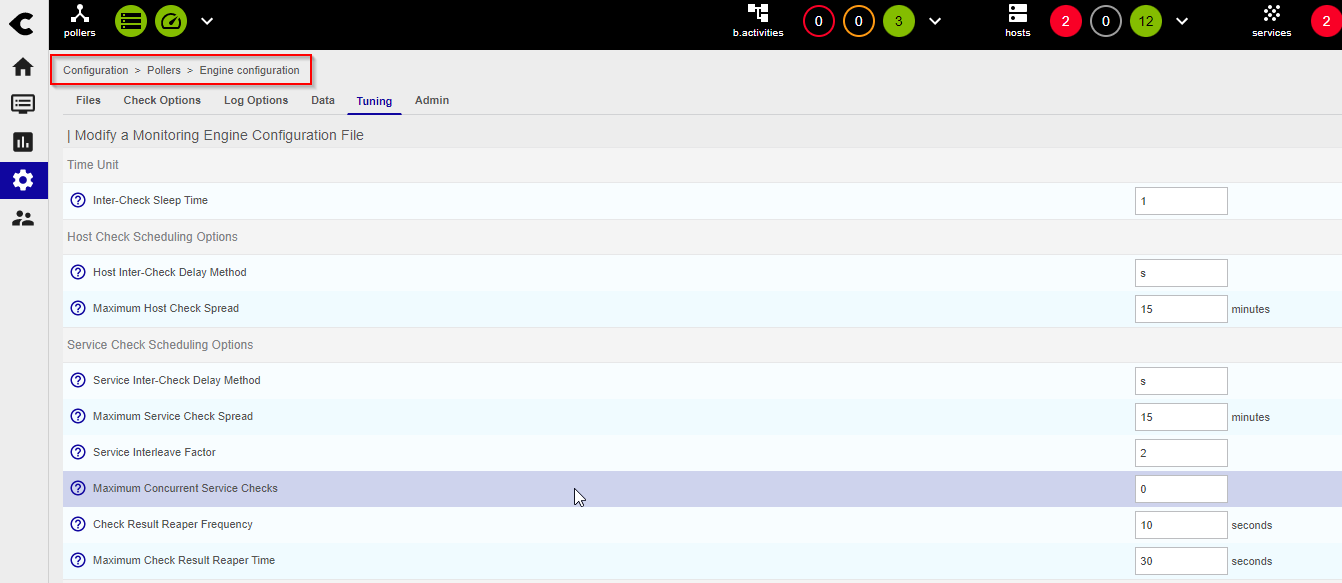
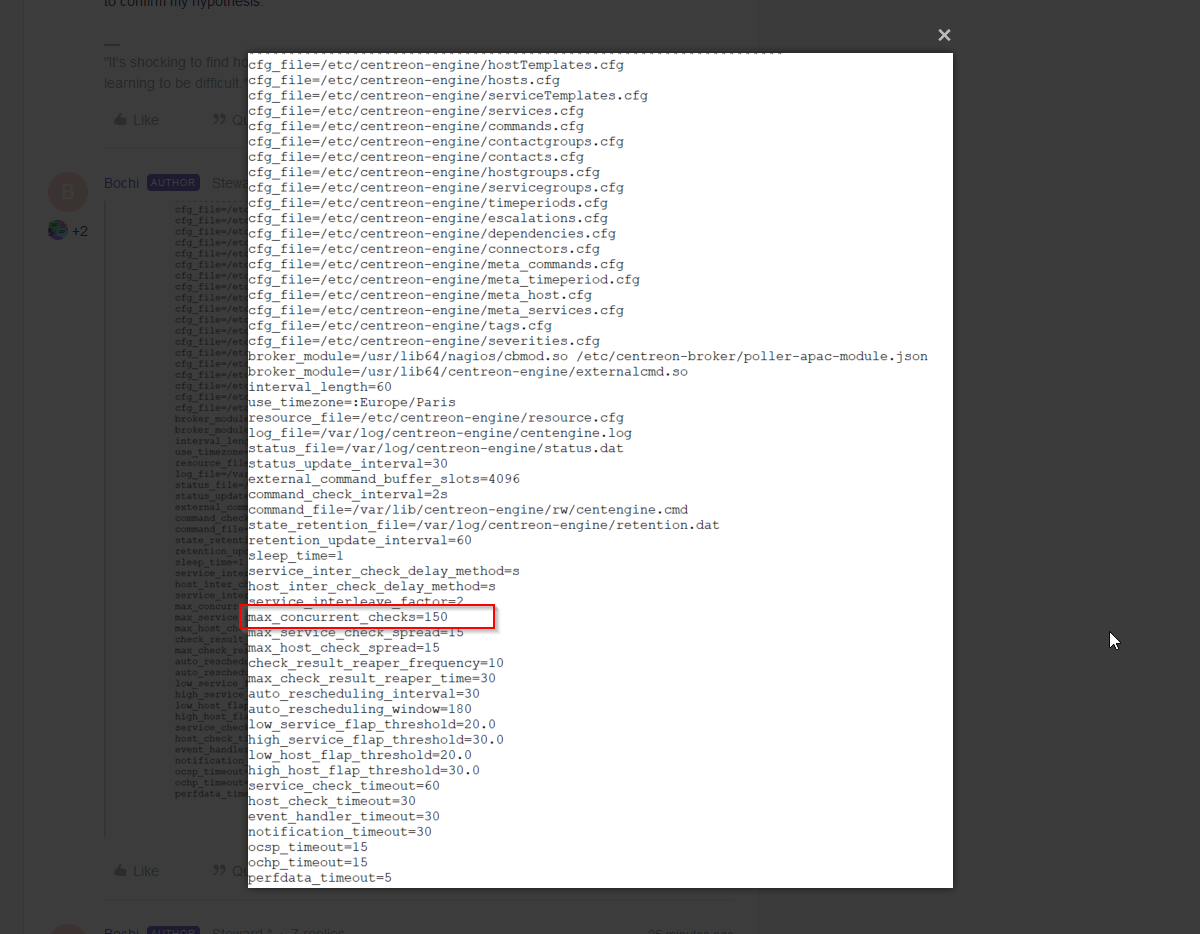
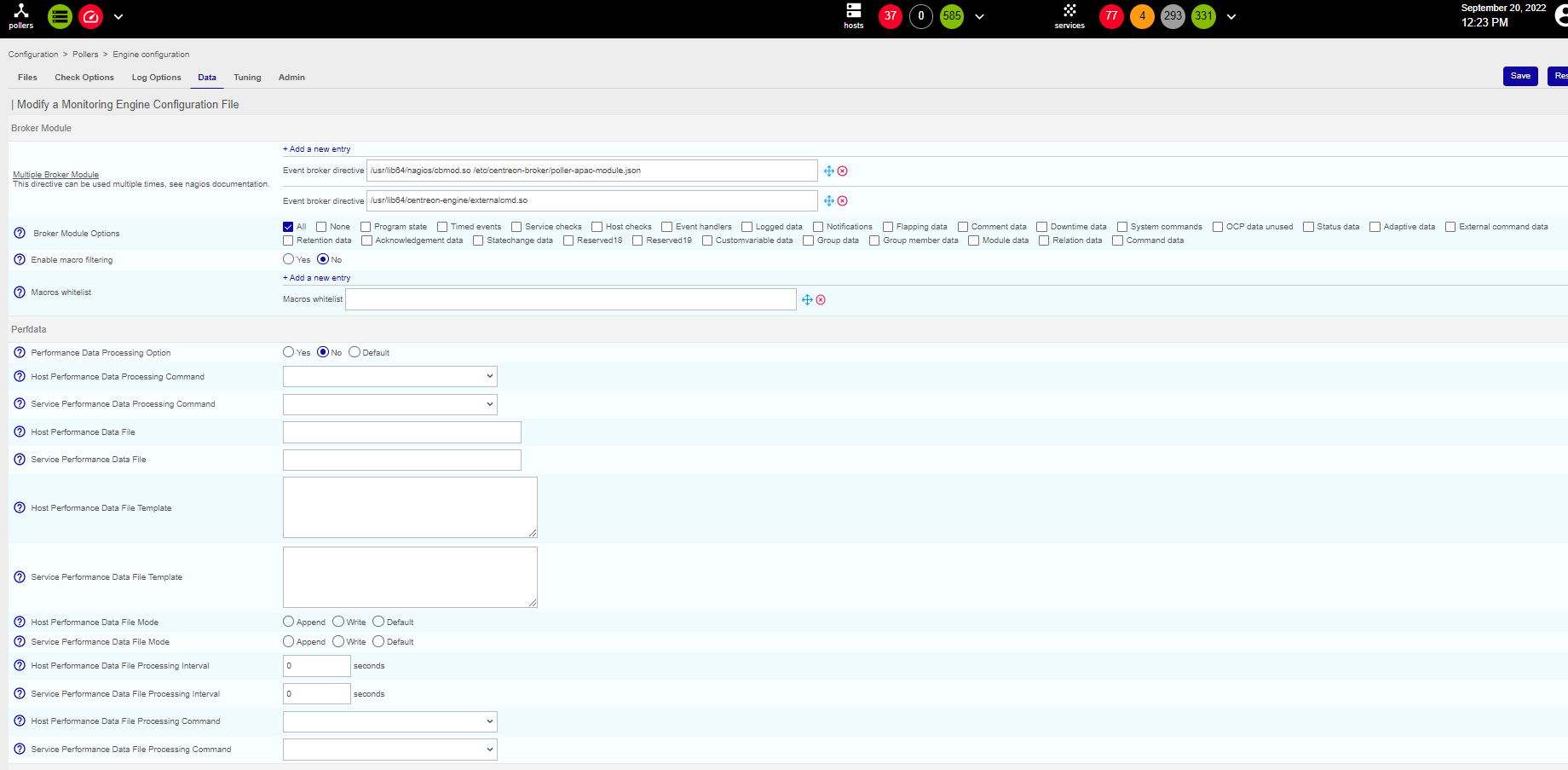
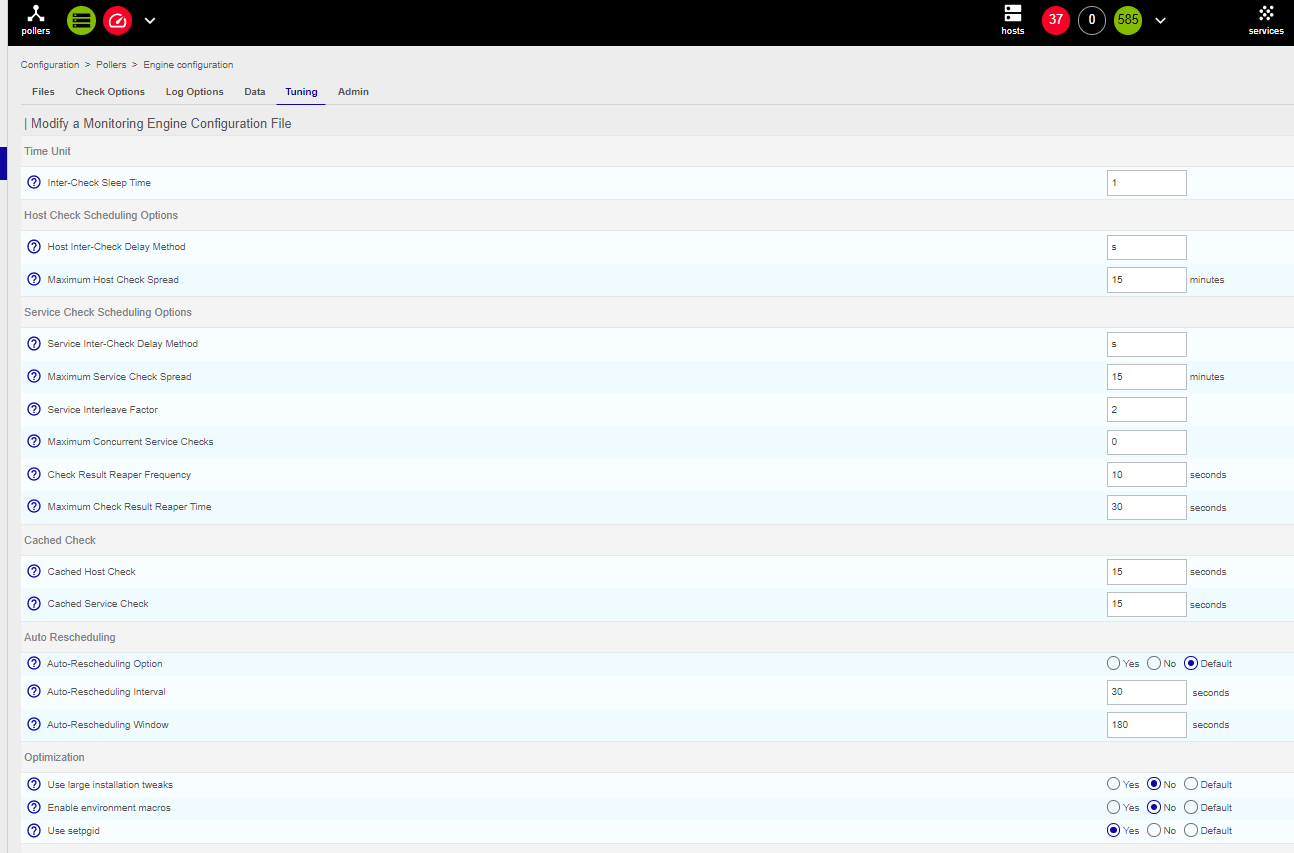
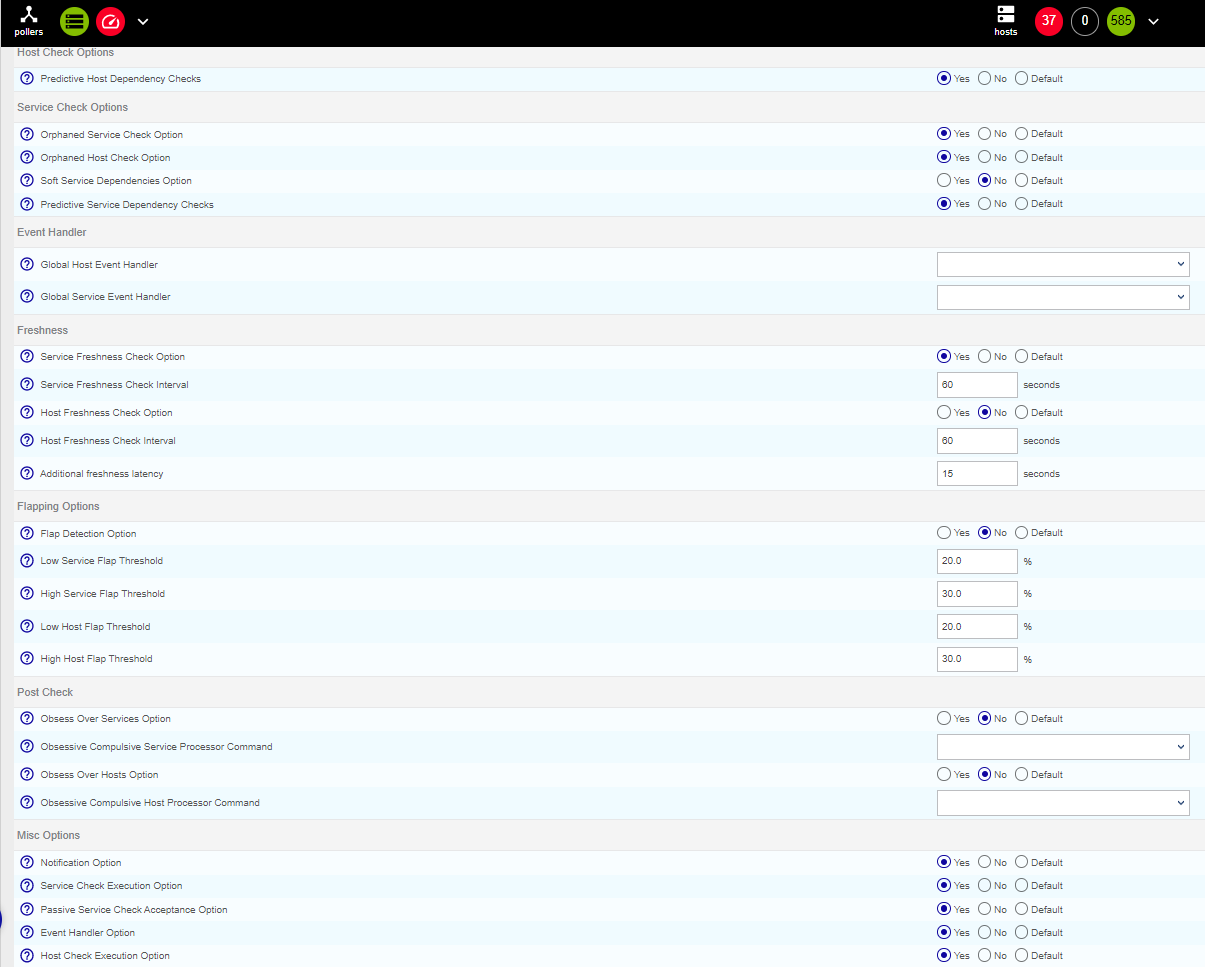
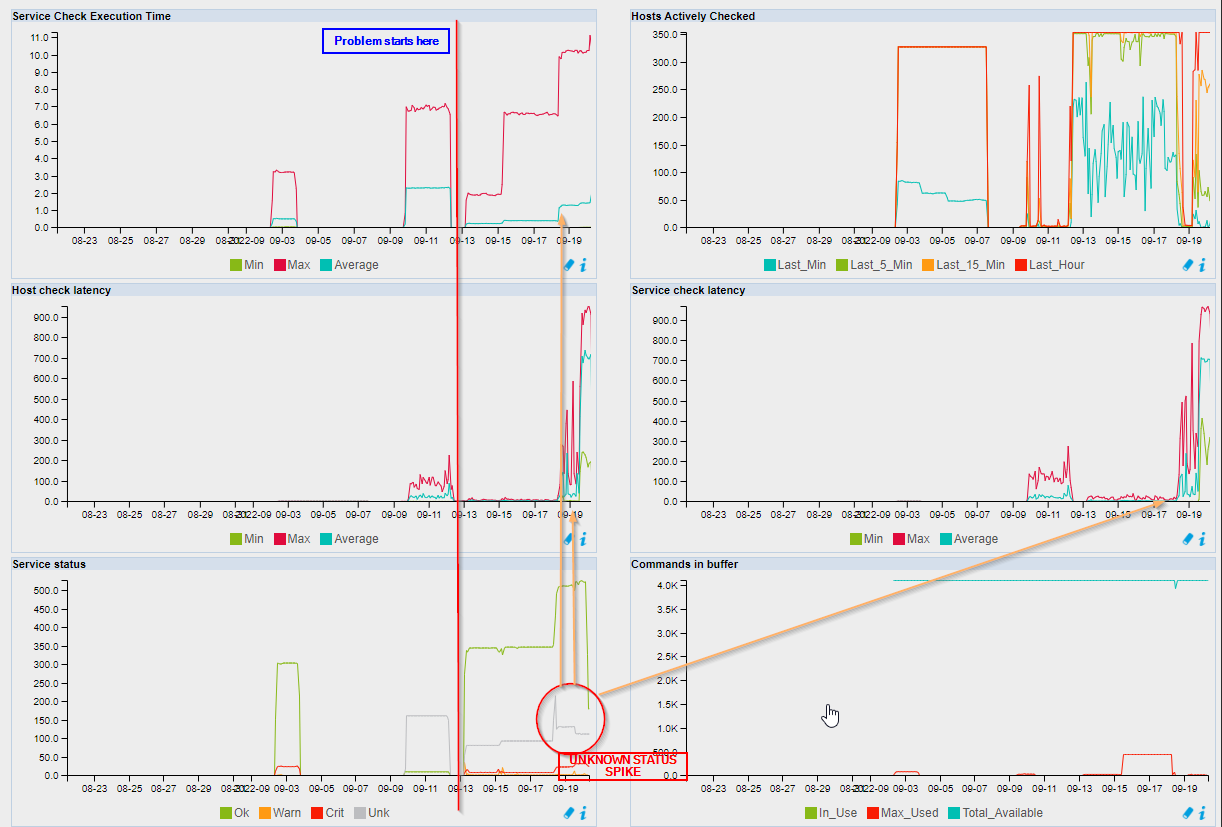
I have an error ‘Latency detected, check configuration for better optimization’, and I see that my graph is not complete…
Help please :)