
Bonjour,
J’ai la page des graphes de statuts de la plateforme qui fonctionne seulement à certaines périodes depuis quelques temps.
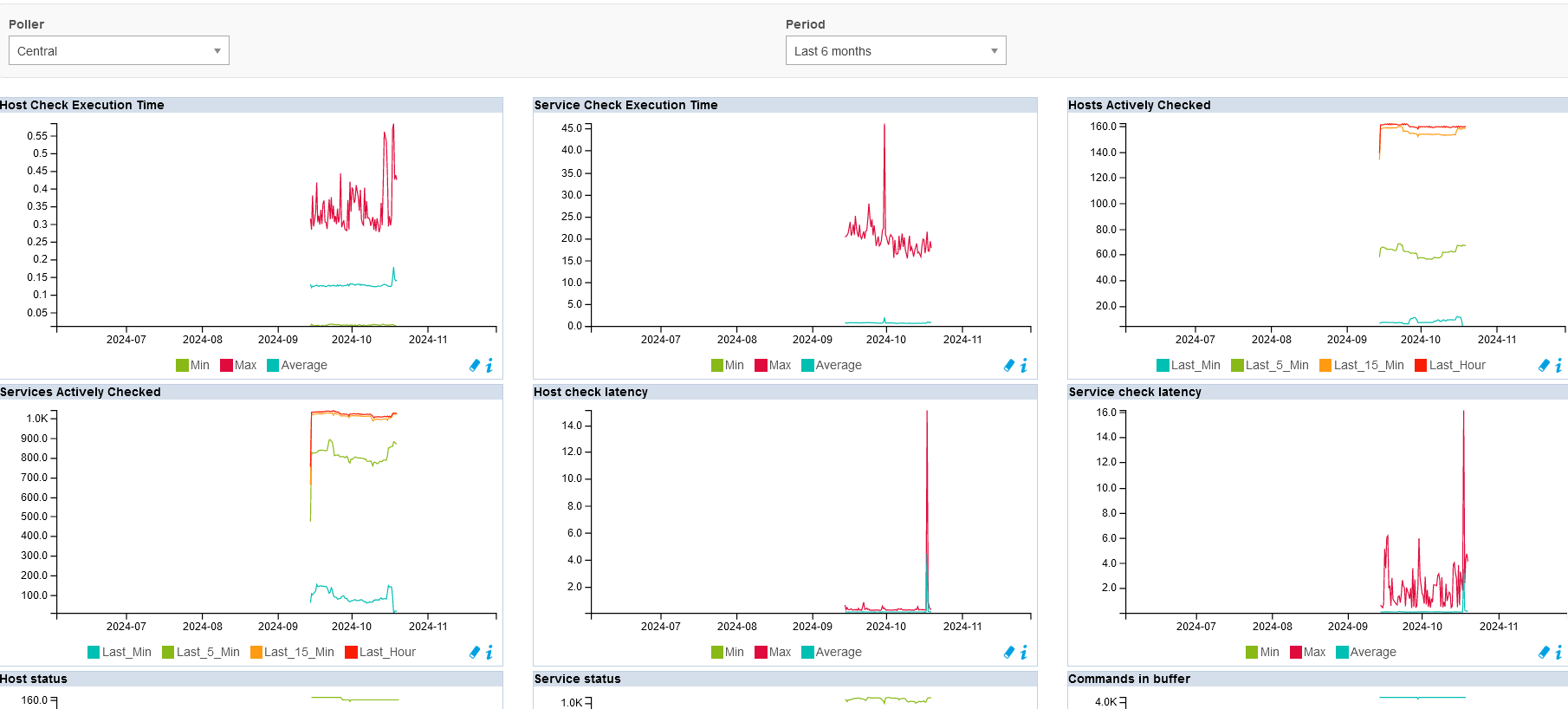
Est-ce que quelqu’un a déjà rencontré un problème similaire, et aurait éventuellement une solution ?

Bonjour,
J’ai la page des graphes de statuts de la plateforme qui fonctionne seulement à certaines périodes depuis quelques temps.
Est-ce que quelqu’un a déjà rencontré un problème similaire, et aurait éventuellement une solution ?
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.

