
Please note that the only procedures supported and maintained by Centreon are those published in the official documentation. If you have a question about this article, post it in the comments.
This guide will present you with the keys to using the collection mode built on the SQL protocol for monitoring Oracle jobs. If you haven't read the overview post "Why Collection Modes?" and "SQL Collection - Tutorial", take a look at them!
As mentioned in the SQL collection tutorial, it is often used to check sql and sql-string to get simple SQL. But when we need to get accurate results on our queries like job monitoring, these modes are not enough. This is where the collection mode comes into play.
Goal
In this tutorial, our job should run every minute. Our goal is to have a service checking the job that the last update is not too far from the present time.
Prerequisites
The basic requirements are the same as the post on "SQL Collection - Tutorial".
You should also add :
- Knowing which job to monitor
Identifying the data
The first step is to determine which job you want to monitor. In our example, the job is called `JOB_OURSYNC`. It comes from the `DBA_SCHEDULER_JOBS` table. Of course, the procedure is the same for Oracle job tables such as
`ALL_SCHEDULER_JOBS` and `USER_SCHEDULER_JOBS`.
In the description of the table, we need these three fields (only the significant fields are shown below)::
SQL> DESCRIBE dba_scheduler_jobs
Name Null? Type
-------------------------------------- -------- -------------------------------
[...]
JOB_NAME VARCHAR2(30)
[...]
STATE VARCHAR2(15)
[...]
LAST_START_DATE TIMESTAMP(6) WITH TIME ZONE
[...]
To retrieve the job information, you can request like :
SELECT job_name, state, to_char(last_start_date, 'DD-MON-YYYY HH24:MI:SS') AS last_run_date FROM dba_scheduler_jobs;
JOB_NAME STATE LAST_RUN_DATE
------------------------------ --------------- ----------------------
XMLDB_NFS_CLEANUP_JOB SCHEDULED
SM$CLEAN_AUTO_SPLIT_MERGE SCHEDULED 11-JANV.-2022 00:00:00
RSE$CLEAN_RECOVERABLE_SCRIPT SCHEDULED 11-JANV.-2022 00:00:00
FGR$AUTOPURGE_JOB SCHEDULED
BSLN_MAINTAIN_STATS_JOB SCHEDULED 10-JANV.-2022 00:00:00
DRA_REEVALUATE_OPEN_FAILURES SCHEDULED 10-JANV.-2022 22:00:00
HM_CREATE_OFFLINE_DICTIONARY SCHEDULED
ORA$AUTOTASK_CLEAN SCHEDULED 11-JANV.-2022 03:00:00
FILE_WATCHER SCHEDULED
PURGE_LOG SCHEDULED 11-JANV.-2022 03:00:00
MGMT_STATS_CONFIG_JOB SCHEDULED 01-JANV.-2022 01:01:01
MGMT_CONFIG_JOB SCHEDULED 11-JANV.-2022 01:01:01
TST$SCHDNEGACTION SCHEDULED 11-JANV.-2022 14:41:27
TST$EVTCLEANUP SCHEDULED 11-JANV.-2022 14:23:45
JOB_OURSYN SCHEDULED 11-JANV.-2022 15:13:57Once we have all information, we can move to the next step.
Creating the configuration file
JSON Overview
As explained in the article "SQL Collection - Tutorial", a good practice is to create a dedicated directory on the Poller file system and to create a file with a meaningful name :
[user@poller ~]# mkdir /etc/centreon-engine/collection-config/
[user@poller ~]# sudo chown centreon-engine. /etc/centreon-engine/collection-config/
[user@poller ~]# touch /etc/centreon-engine/collection-config/collection-oracle-job-sync.json
Now let's look at the overall structure of JSON:
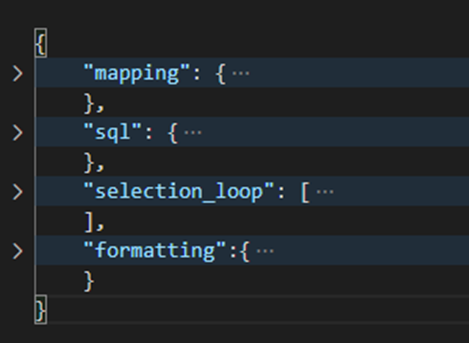
JSON node: mapping (optional)
The Mapping node is not mandatory. It contains instructions to transform the collected data into a more usable/readable format.
In our case, we don't need it because we don't have any fields that have the tinyint type as an instance. So it is not needed.
JSON node: SQL (mandatory)
The SQL node is mandatory. It describes the values you want to monitor. The structure of this part is the same as that of the SQL language. In our case, it will look like this:

The above definition gives instructions to the mode to:
- Get data from a SQL table (tables).
- Identify the name of the table entry (name) and the query (query).
- Select interesting fields (entries)
-
SQL
For the query, the construction is particular. It is necessary to have the current time minus the last execution of the job, and this, in timestamp format. The difficulty is that in Oracle SQL, the expression of the timestamp is different from that of the Unix format that we know. For subtraction or comparison calculations, it is much easier and more secure to do so with integers than with dates and times.
The Oracle timestamp looks like this : 01-JAN-03 02:00:00.000000 AM, and we need the date to be : 1649929396. Therefore, the Oracle conversion methods should be used as below.
Taking the example of last_start_date fields, first, you have to extract the date from the field in UTC with the method sys_extract_utc.
sys_extract_utc(last_start_date)Then return this result as a timestamp Oracle with the cast function.
cast(sys_extract_utc(last_start_date) AS date)Then subtract the start date from the timestamp TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS') :
cast(sys_extract_utc(last_start_date) AS date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')And to get the date in UNIX timestamp (i.e. epoch), multiply it by 86400 :
(cast(sys_extract_utc(last_start_date) AS date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400)At this stage the result is still not satisfactory because it will give us float number and not integer. So we are forced to truncate the result with the trunc function..
trunc((cast(sys_extract_utc(last_start_date) AS date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400)It is a long process, but it is the only way to get a good result.
To calculate the time between the two, you have to redo the operations and use the same functions by subtracting the last_start_date from the current time :
trunc(((cast(sysdate as date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400) - ((cast(sys_extract_utc(last_start_date) AS date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400)) AS delay
-
Entries
For the entries, the ones mentioned in the request must be included:
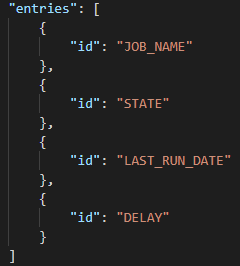
This must be the exact name of the columns defined in the query, like LAST_RUN_DATE and DELAY in our case.
JSON node: selection_loop
This part keeps the same basis as the previous post.
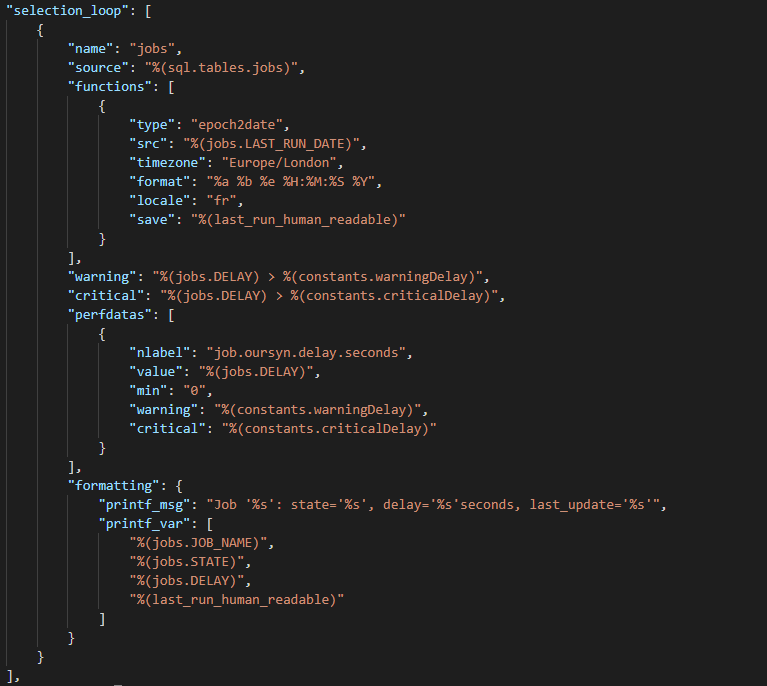
For the function part, you have to pay attention to the timezone because it would have a time lag. At this point, all our results are in Europe/London for the timezone. But if yours is different, think about adapting it.
It is in this function that we will have the right final format that will be displayed in Centreon for your service.
The perfdatas are formatted as explained above because the need was to see the delta in seconds and be able to put thresholds if the delta exceeds so many seconds. But it will be up to you to apply it in minutes or hours, depending on the execution of your job.
In the formatting section, you can set the message as you like, but it must be based on the entries defined in the SQL section. Just the last one is different because there was the treatment in function.
JSON node: formatting (optional)
The last section of the file is a global formatting message (custom_message_global) when everything is OK and there is more than one job. In our case, we have only one job and recommend keeping one JSON file per job, like for traffic or disks.

Get and execute the Plugin?
As indicated in the Centreon documentation, you have to install the plugin on the different Pollers that do Oracle Database checks like :
[user@poller ~] sudo yum install centreon-plugin-Applications-Databases-Oracle
Then create the command to call App-DB-Oracle-Job in Configuration > Commands > Checks:
$CENTREONPLUGINS$/centreon_oracle.pl --plugin=database::oracle::plugin --hostname='$HOSTADDRESS$' --port='$_HOSTORACLEPORT$' --sid='$_HOSTORACLESID$' --servicename='$_HOSTORACLESERVICENAME$' --username='$_HOSTORACLEUSERNAME$' --password='$_HOSTORACLEPASSWORD$' --mode='collection' --config='$_SERVICECONFIGFILEJSON$' --constant='warningDelay=$_SERVICEWARNING$' --constant='cricalDelay=$_SERVICECRITICAL$' $_SERVICEEXTRAOPTIONS$/!\ Small subtlety in the command, in the constant part, we see the name of the constants defined in our JSON file. Parameter to adapt according to your JSON file
Then create the Service Template you will reuse for all your Oracle jobs :
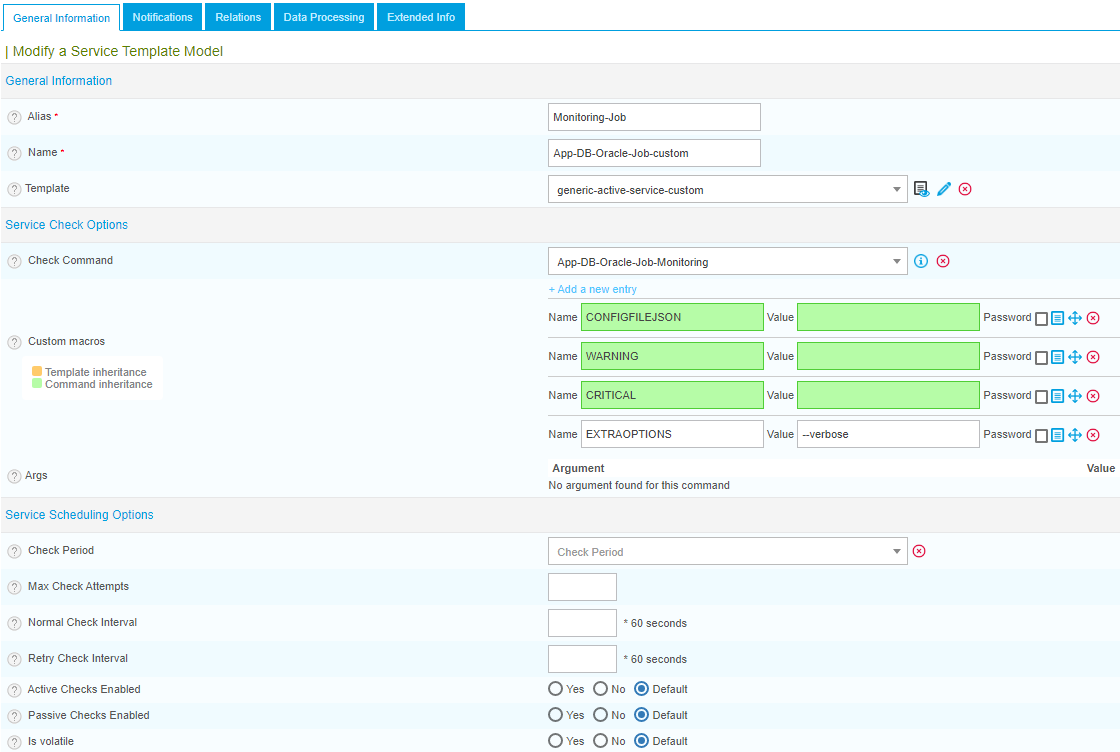
Make sure to use our generic-active-service-custom service model. This is important to keep the inheritance of the basic parameters like all other services. You call your previously created command, and the macros will add themselves.
Then, you create your service by putting the absolute path of the JSON file in the CONFIGFILEJSON macro, as well as your thresholds:
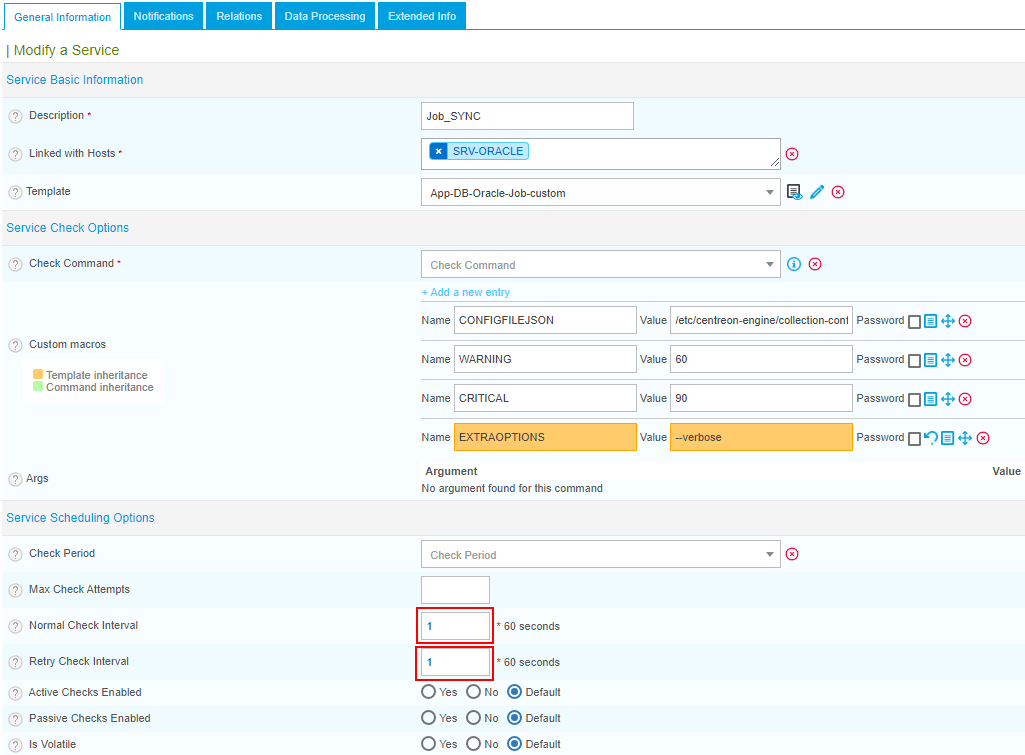
Remember to adjust your Normal Check Interval and Retry Check Interval to suit your use case. For us, we set it at 1 minute each because the job runs every minute.
Thus, you will get results like this:
-bash-4.2$ /usr/lib/centreon/plugins/centreon_oracle.pl --plugin=database::oracle::plugin --mode='collection' --hostname=<oracle_db_host> --port='<oracle_port_db>' --sid='<db_sid>' --servicename='' --username='<db_username>' --password='<db_password>' --config='/etc/centreon-engine/collection-config/collection-oracle-job-sync.json' --verbose --debug
OK: Job 'JOB_SYNC': state='SCHEDULED', delay='8'seconds, last_update='ven. mars 18 10:17:29 2022' | 'job.sync.delay.seconds'=8;10;90;0;
- Tips :
When running the plugin, if you have this kind of output, it means the timestamp conversion is not made correctly.
-bash-4.2$ /usr/lib/centreon/plugins/centreon_oracle.pl --plugin=database::oracle::plugin --mode='collection' --hostname=xxx.xx.xxx.xxx --port='1522' --sid='xxxxx' --servicename='' --username='centreon' --password='xxxxxxxx' --config='/etc/centreon-engine/collection-config/collection-oracle-job-oursyn.json' --verbose --debug
UNKNOWN: The 'epoch' parameter ("1647597149,999999999999999999999999999997") to DateTime::from_epoch did not pass regex check
at /usr/lib64/perl5/vendor_perl/DateTime.pm line 504.
DateTime::from_epoch(undef, 'epoch', '1647597149,999999999999999999999999999997', 'time_zone', 'Europe/Londres', 'locale', 'fr') called at /usr/lib/centreon/plugins/centreon_oracle.pl line 1003
centreon::common::protocols::sql::mode::collection::exec_func_epoch2date('centreon::common::protocols::sql::mode::collection=HASH(0x314...', 'save', '%(last_run_human_readable)', 'format', '%a %b %e %H:%M:%S %Y', 'timezone', 'Europe/Londres', 'src', '%(jobs.LAST_RUN_DATE)', ...) called at /usr/lib/centreon/plugins/centreon_oracle.pl line 1133
centreon::common::protocols::sql::mode::collection::set_functions('centreon::common::protocols::sql::mode::collection=HASH(0x314...', 'section', 'selection_loop > 0 > functions', 'functions', 'ARRAY(0x2e0cfe8)', 'position', 'after_expand', 'default', 1, ...) called at /usr/lib/centreon/plugins/centreon_oracle.pl line 1291
centreon::common::protocols::sql::mode::collection::add_selection_loop('centreon::common::protocols::sql::mode::collection=HASH(0x314...') called at /usr/lib/centreon/plugins/centreon_oracle.pl line 1355
centreon::common::protocols::sql::mode::collection::manage_selection('centreon::common::protocols::sql::mode::collection=HASH(0x314...', 'sql', 'database::oracle::dbi=HASH(0x2bd9320)') called at /usr/lib/centreon/plugins/centreon_oracle.pl line 7045
centreon::plugins::templates::counter::run('centreon::common::protocols::sql::mode::collection=HASH(0x314...', 'sql', 'database::oracle::dbi=HASH(0x2bd9320)') called at /usr/lib/centreon/plugins/centreon_oracle.pl line 5800
centreon::plugins::script_sql::run('database::oracle::plugin=HASH(0x2bd88d0)') called at /usr/lib/centreon/plugins/centreon_oracle.pl line 5539
centreon::plugins::script::run('centreon::plugins::script=HASH(0x25e23d0)') called at /usr/lib/centreon/plugins/centreon_oracle.pl line 13486Once the timestamp is correctly converted, the problem will be resolved.
How to apply my thresholds?
As explained in the other post, we need to define constants :
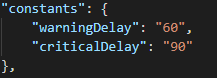
In our case, since the task runs every minute, it should not exceed 60 seconds. Therefore, we started with the predicate that if the time reaches 60 seconds, the service goes into warning mode. This would potentially be in the case of processing latency. On the other hand, if it reaches 90 seconds, there is a real issue and the service becomes critical.
The strict comparison is done in the selection_loop section, just before the perfdatas part.
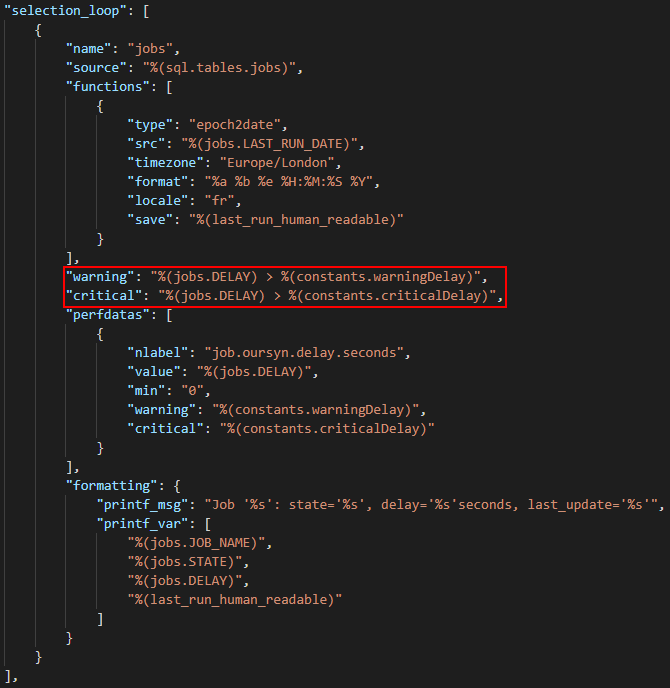
This allows the plugin to function properly:
-bash-4.2$ /usr/lib/centreon/plugins/centreon_oracle.pl --plugin=database::oracle::plugin --mode='collection' --hostname=<centreon_db_host> --port='1522' --sid='<db_sid> --servicename='' --username='<db_user>' --password='<db_password>' --config='/etc/centreon-engine/collection-config/collection-oracle-job-syn.json' --verbose
WARNING: Job 'JOB_SYN': state='SCHEDULED', delay='15'seconds, last_update='ven. mars 18 10:17:29 2022' | 'job.syn.delay.seconds'=15;10;90;0;
How you can help?
You guessed it. This mode also enables you to monitor anything without writing any line of code. So, when you build a JSON configuration file that could benefit to other community members, share it on centreon-plugins GitHub or in a dedicated topic on your favorite community platform!
Centreon Support does not actively maintain knowledge articles. If you have questions or require assistance with an article, please create a case or post a comment below.
Attachment
collection-oracle-job-sync.json file
{
"constants": {
"warningDelay": "60",
"criticalDelay": "90"
},
"mapping": {
"state": {
"0": "not running",
"1": "running"
}
},
"sql": {
"tables": [
{
"name": "jobs",
"query": "SELECT job_name, state, trunc((cast(sys_extract_utc(last_start_date) as date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400) AS last_run_date, trunc(((cast(sysdate as date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400) - ((cast(sys_extract_utc(last_start_date) as date) - TO_DATE('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')) * 86400)) AS delay FROM dba_scheduler_jobs WHERE job_name='JOB_SYNC'",
"entries": [
{
"id": "JOB_NAME"
},
{
"id": "STATE"
},
{
"id": "LAST_RUN_DATE"
},
{
"id": "DELAY"
}
]
}
]
},
"selection_loop": [
{
"name": "jobs",
"source": "%(sql.tables.jobs)",
"functions": [
{
"type": "epoch2date",
"src": "%(jobs.LAST_RUN_DATE)",
"timezone": "Europe/London",
"format": "%a %b %e %H:%M:%S %Y",
"locale": "fr",
"save": "%(last_run_human_readable)"
}
],
"warning": "%(jobs.DELAY) > %(constants.warningDelay)",
"critical": "%(jobs.DELAY) > %(constants.criticalDelay)",
"perfdatas": [
{
"nlabel": "job_sync.delay.seconds",
"value": "%(jobs.DELAY)",
"min": "0",
"warning": "%(constants.warningDelay)",
"critical": "%(constants.criticalDelay)"
}
],
"formatting": {
"printf_msg": "Job '%s': state='%s', delay='%s'seconds, last_update='%s'",
"printf_var": [
"%(jobs.JOB_NAME)",
"%(jobs.STATE)",
"%(jobs.DELAY)",
"%(last_run_human_readable)"
]
}
}
],
"formatting": {
"custom_message_global": "All Jobs are OK"
}
}
